雷池社区版动态防护功能小测之JS动态混淆功能分析
|
这是雷池社区版动态防护功能小测的下篇。
雷池在 v6.2.0 版本中对动态防护功能的能力进行了进一步释放,新版本不仅支持了不限数量的动态加密,还在专业版中支持快速加解密,JS 防护能力也取消了数量限制。
今天我们以 v6.3.0 版本为例,分析一下雷池的 JS 动态混淆功能。
组件架构
依托于 t1k-c 优秀的能力,可以对 Tengine 反代的 Response Type 及 Response Body 进行检测。负责 JS 加密的程序是 safeline-chaos,和之前 HTML 动态防护是同一个组件。
动态混淆测试
我们先用一个最简单的例子,看一下动态混淆大概做了哪些工作。
这是原 JS 文件的代码:
var $hello = 'world';
// for leichi
function test(){
console.log('hello leichi.');
}
let fun = function(){
console.log('hello fun');
}
var $hello = 'world';
// for leichi
function test(){
console.log('hello leichi.');
}
let fun = function(){
console.log('hello fun');
}
// es6
class Point {
constructor(x, y) {
this.x = x;
this.y = y;
}
toString() {
return '(' + this.x + ', ' + this.y + ')';
}
}
代码逻辑很简单,有变量,密码,函数,类,以及注释。原始 JS 的大小为 502B。
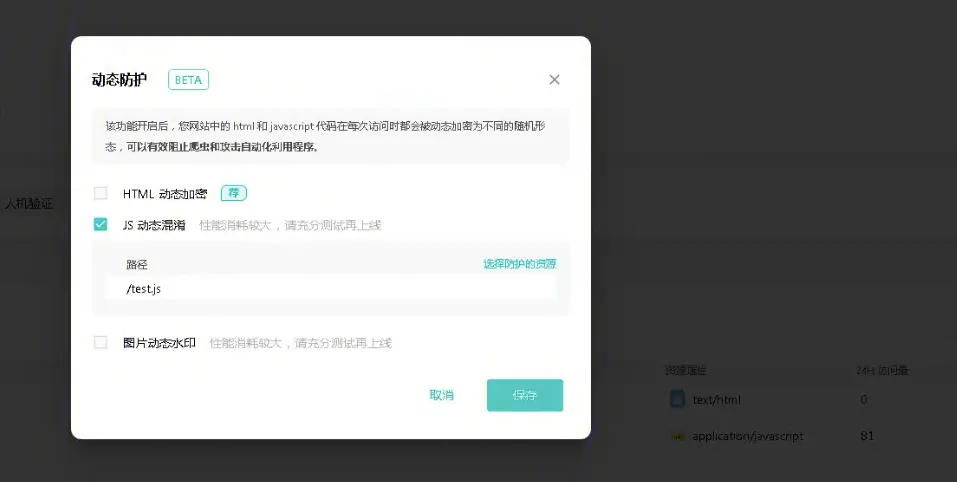
我们开启 JS 动态防护,在开启前需要先识别到这个资源,如果雷池识别不到这个资源,则无法对其进行防护处理。
开启动态防护后,我们发现原 JS 已经变成了我们不认识的模样了。
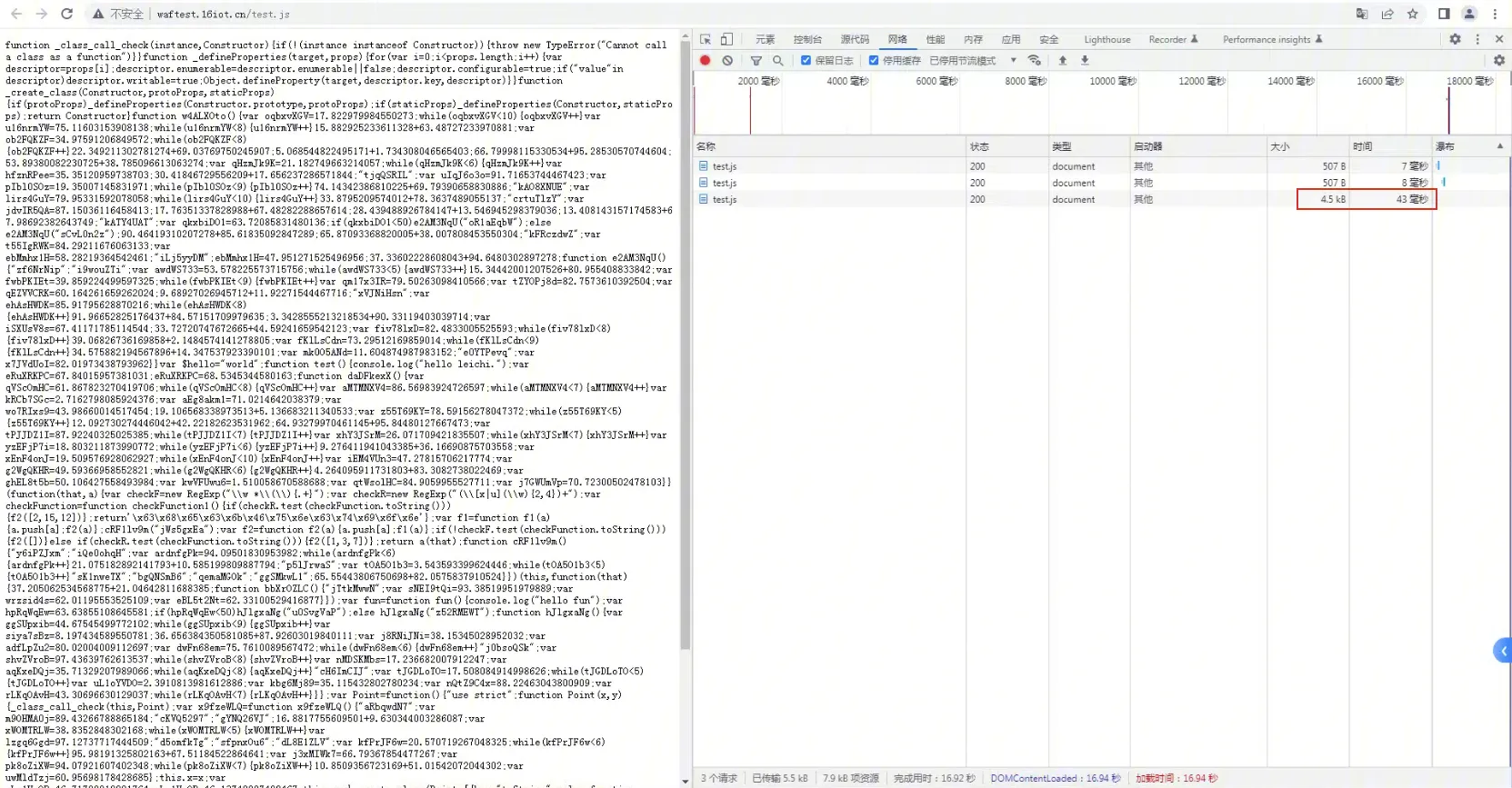
多次刷新,每次生成的代码不一样的。膨胀到 4.5kB 到 5.9kB 左右。代码中的注释被去掉了,并且增加了很多干扰代码。
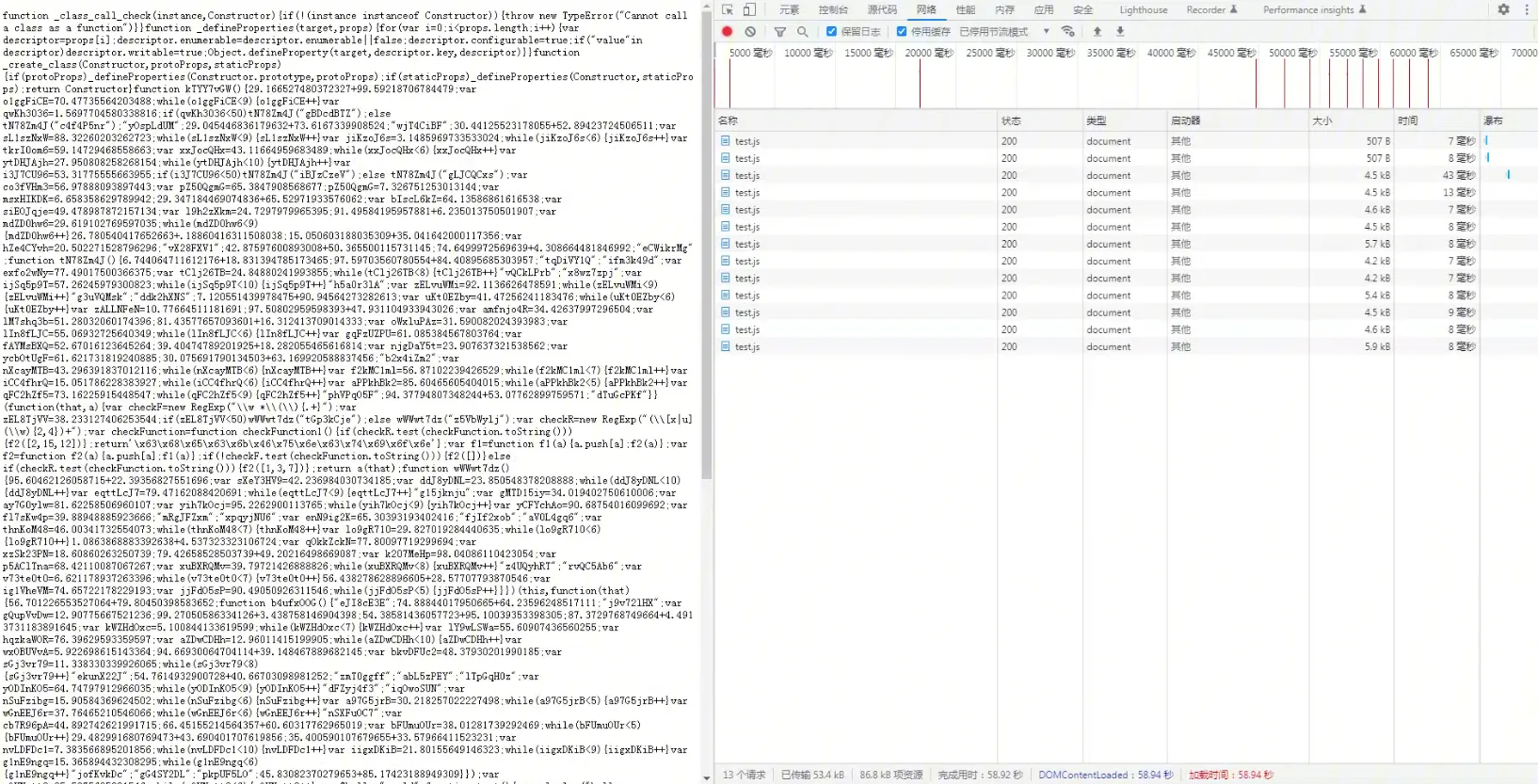
混淆特征分析
虽然 JS 加密是动态的,但是我们可以对静态代码进行分析。
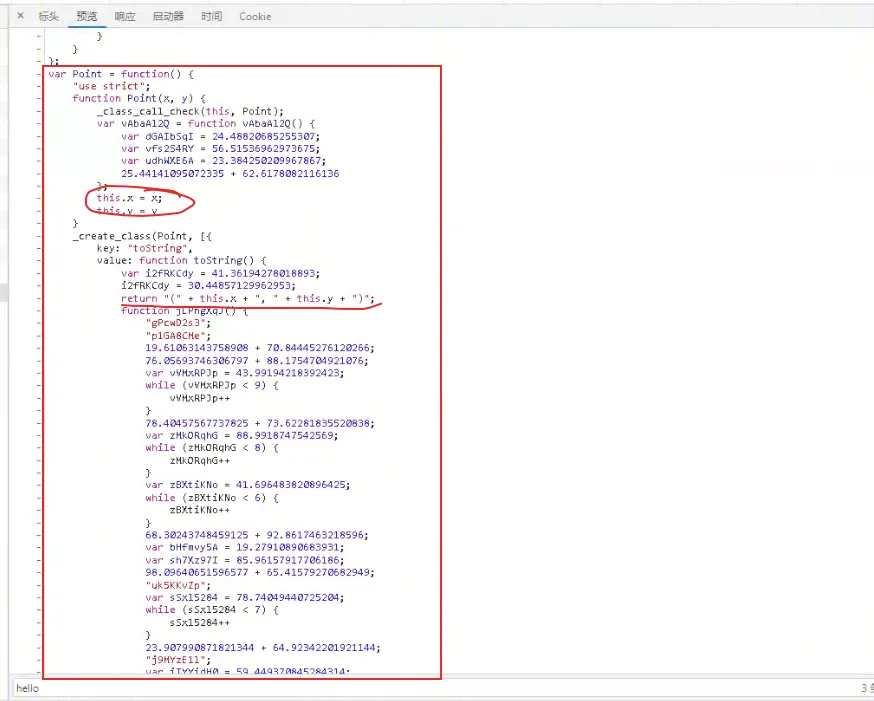
如果根据原 JS 中的代码在动态混淆后的代码中进行搜索,我们可以发现,动态混淆并未对变量和函数进行替换,原来的变量、函数仍然保留原来的名称和代码,更多的是在原来的代码中增加了一些干扰代码。
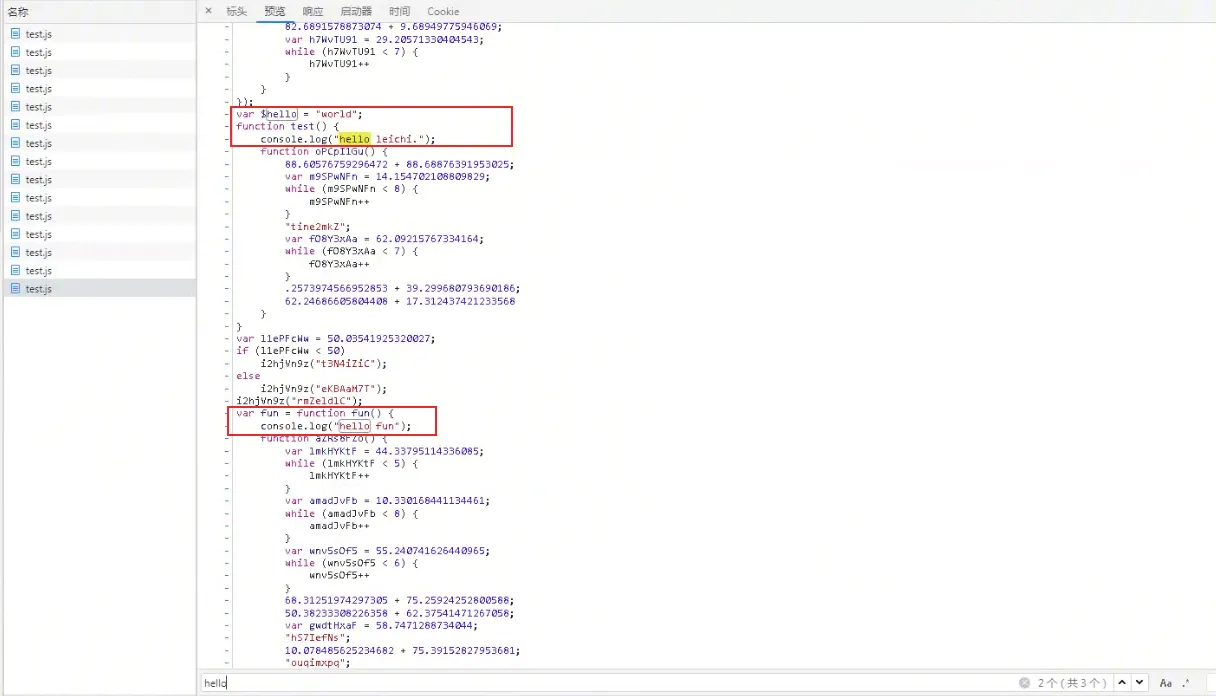
这些代码大体上的特征就是
1、随机字符串的函数名,如下图:
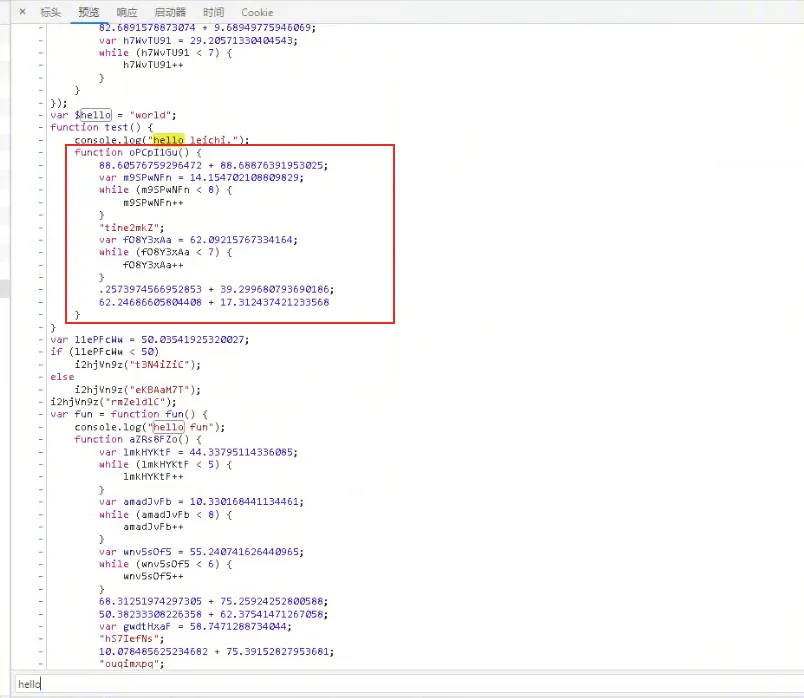
2、var 随机字符串 = 浮点数 3、var 随机字符串 = 浮点数,紧接着 while 或者 if 判断一下,但是条件不成立。
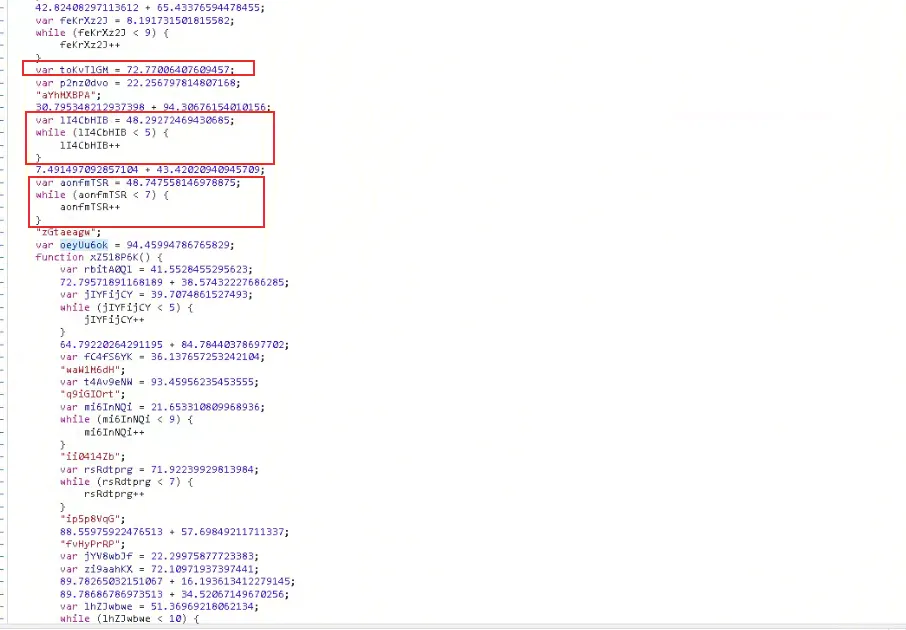
4、浮点数相加的代码,纯字符的代码
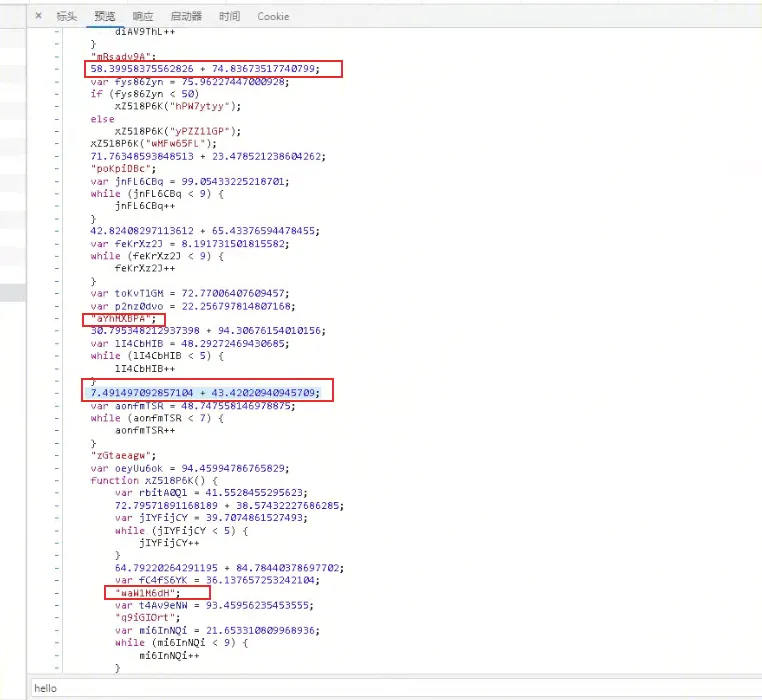
5、对于类代码(ES6 语法),会进行编译。
等等……
一些思考
1、大体积 JS 动态混淆过程中,消耗的 CPU 资源还是比较高的。这个雷池也给予了提示,大家合理使用这个功能即可。
我的个人理解,作为一些现代化的前端工程,一般 build 时候会自带混淆和 JS 压缩,这类的 JS 已经失去了可读性,并有较高的执行效率,没有必要在进行二次动态混淆了。我们可以将这个功能重点放在未混淆压缩的 JS 上。
2、动态混淆的代码,极大的降低了代码的可读性,但是混淆后的代码有一些特征还是可以被抓到并且分析的。毕竟前端没有秘密,我们能做的就是尽可能的增加破解的成本。